Accepted paper: “MROP: Modulated Rank-One Projections for compressive radio interferometric imaging” by Olivier Leblanc, Chung San (Taylor) Chu, Laurent Jacques, and Yves Wiaux at Monthly Notices of the Royal Astronomical Society. See the paper here.
Welcome to ISPGroup!
The Image and Signal Processing Group of UCLouvain, ICTEAM, Belgium, whose members are listed here, is active in many theories, models, techniques, codes, datasets, and codecs related to signal and image processing in a broad sense.
For instance, the ISPGroup researchers work on signal acquisition, compression and streaming; machine and deep learning for computer vision; (multiple) object tracking; content-based data retrieval; biomedical signal and medical image processing; compressed sensing and inverse problem solving, compputational imaging; hyperspectral imaging; tomographic methods; sparse signal representation; data restoration, … and many other topics described in some of these posts, these publications, and in this visual—and clickable—word cloud:
Aug 19, 2025
Jun 21, 2025
Accepted paper: “Compressive radio-interferometric sensing with random beamforming as rank-one signal covariance projections” by Olivier Leblanc, Yves Wiaux, and Laurent Jacques at IEEE Transactions on Computational Imaging. See the paper here.
Aug 14, 2024
Accepted paper: “MPL: Lifting 3D Human Pose from Multi-view 2D Poses” by Seyed Abolfazl Ghasemzadeh, A. Alahi, and C. De Vleeschouwer, to be presented at “T-CAP: Towards a Complete Analysis of People: Fine-grained Understanding for Real-World Applications” workshop at the European Conference on Computer Vision (ECCV, Milan, 1-4 Oct 2024).
MPL is a 3D human pose lifter that takes multi-view 2D poses as its inputs. The main challenge in multi-view 3D human pose estimation is lack of real-life images paired with 3D. This challenge is bypassed in MPL by relying on a two-stage framework consisting of an off-the-shelf 2D pose estimator and a multi-view 3D pose lifter. More information here
Aug 14, 2024
Accepted paper: “Sequential Representation Learning via Static-Dynamic Conditional Disentanglement " by Mathieu Cyrille Simon, Pascal Frossard and Christophe De Vleeschouwer (arXiv preprint), to be presented at the European Conference on Computer Vision (ECCV, Milan, 1-4 Oct 2024).
Unsupervised disentangled representation learning within sequential data, focusing on separating time-independent and time-varying factors in videos. This disentanglement is expected to facilitate numerous downstream generation or classification tasks and enhance model explainability.
-
NH-DEHAZE: Dataset and dehazing methods for non-homogeneous and dense hazy scenes
 In presence of haze, small floating particles absorb and scatter the light from its propagation direction. This results in selective and significant attenuation of the light spectrum and causes hazy scenes to be subject to a loss of contrast and sharpness for distant objects.Jun 25, 2025
In presence of haze, small floating particles absorb and scatter the light from its propagation direction. This results in selective and significant attenuation of the light spectrum and causes hazy scenes to be subject to a loss of contrast and sharpness for distant objects.Jun 25, 2025 -
Signal Processing after quadratic sketching
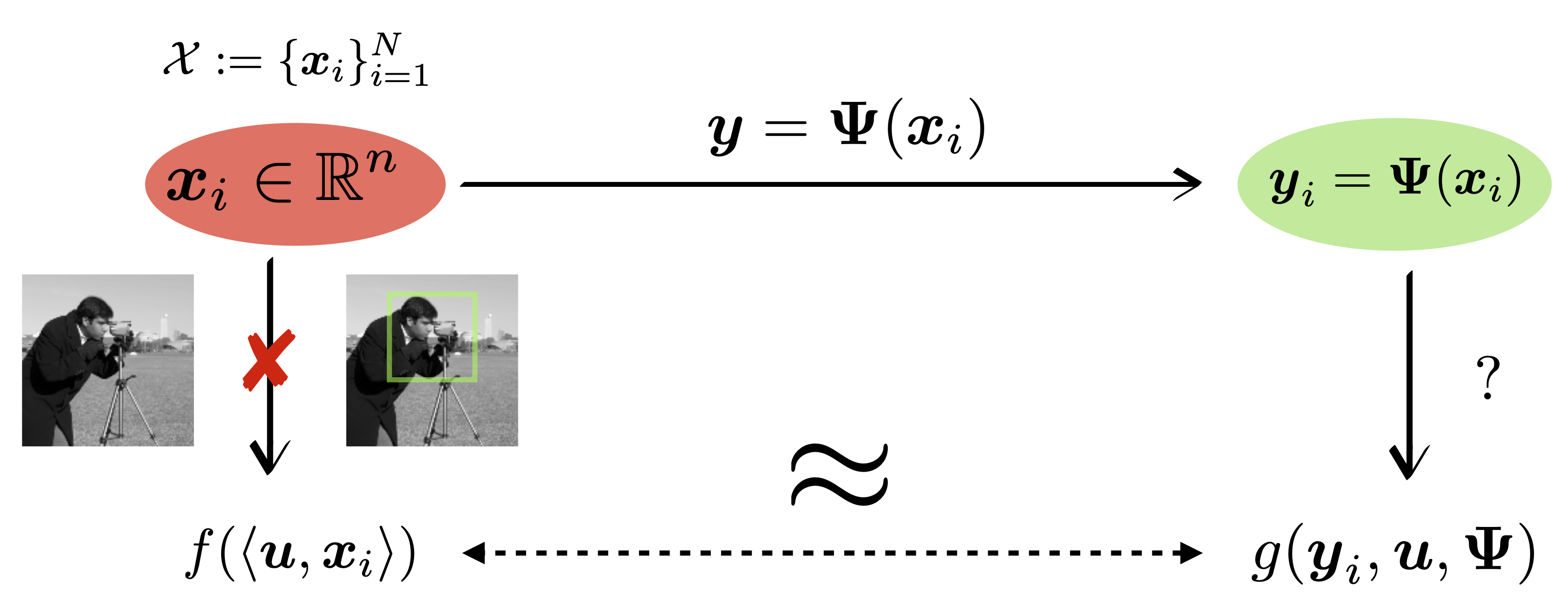 Sketching is a commonly used technique in signal processing. In this short piece we describe how to estimate functions of a given signal based solely on its sketch and without explicit reconstruction.Nov 20, 2023
Sketching is a commonly used technique in signal processing. In this short piece we describe how to estimate functions of a given signal based solely on its sketch and without explicit reconstruction.Nov 20, 2023 -
Body Part-Based Representation Learning for Occluded Person Re-Identification
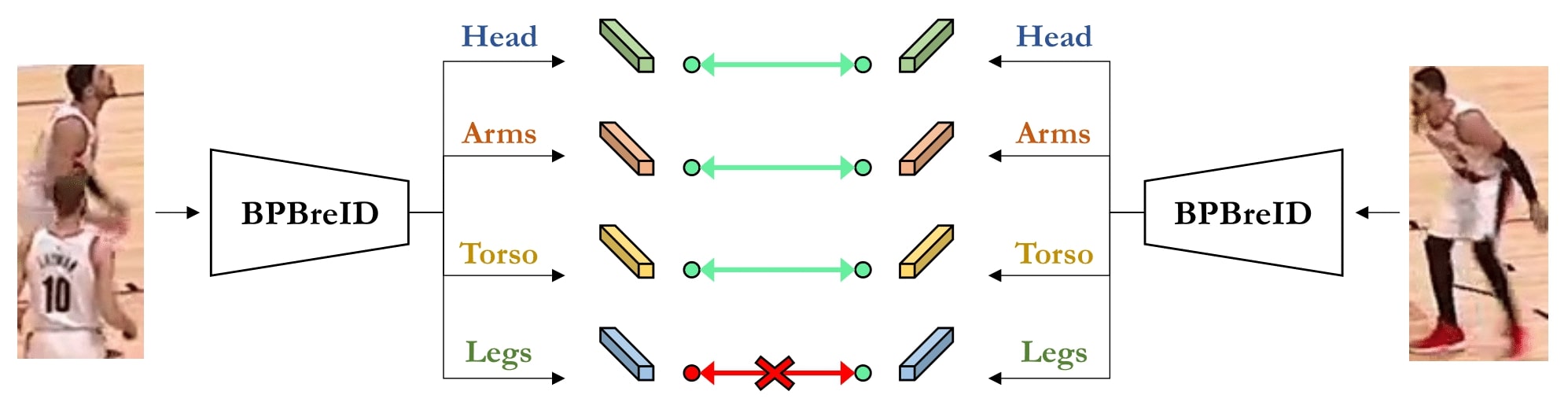 BPBReID, a part-based re-identification method using body part feature representations to compute to similarity between two person images.Jul 3, 2023
BPBReID, a part-based re-identification method using body part feature representations to compute to similarity between two person images.Jul 3, 2023