Online Convolutional Dictionary Learning for Multimodal Imaging

Multimodal imaging systems acquire several measurements of an object using multiple distinct sensing modalities. Often, the data acquired from the sensors is jointly processed to improve the imaging quality in one or more of the acquired modalities. Such imaging methods have the potential to enable new capabilities in traditional sensing systems, providing complementary sources of information about the object. Some applications of multimodal imaging include remote sensing [Entry not found - dalla2015challenges], combining modalities such as synthetic aperture radar, LIDAR, optical and thermal range, multispectral and hyperspectral devices; biomedical imaging, for instance [Entry not found - fatakdawala2013multimodal], where fluorescence lifetime imaging, ultrasound backscatter microscopy, and photoacoustic imaging are combined for imaging cancer in live patients, or [Entry not found - boreal:175260], where CT based geometrical priors are used for blind deconvolution of PET images; and high-resolution depth sensing [Entry not found - diebel2005application] (also considered in this work) where information from an intensity image is used to increase a depthmap resolution.
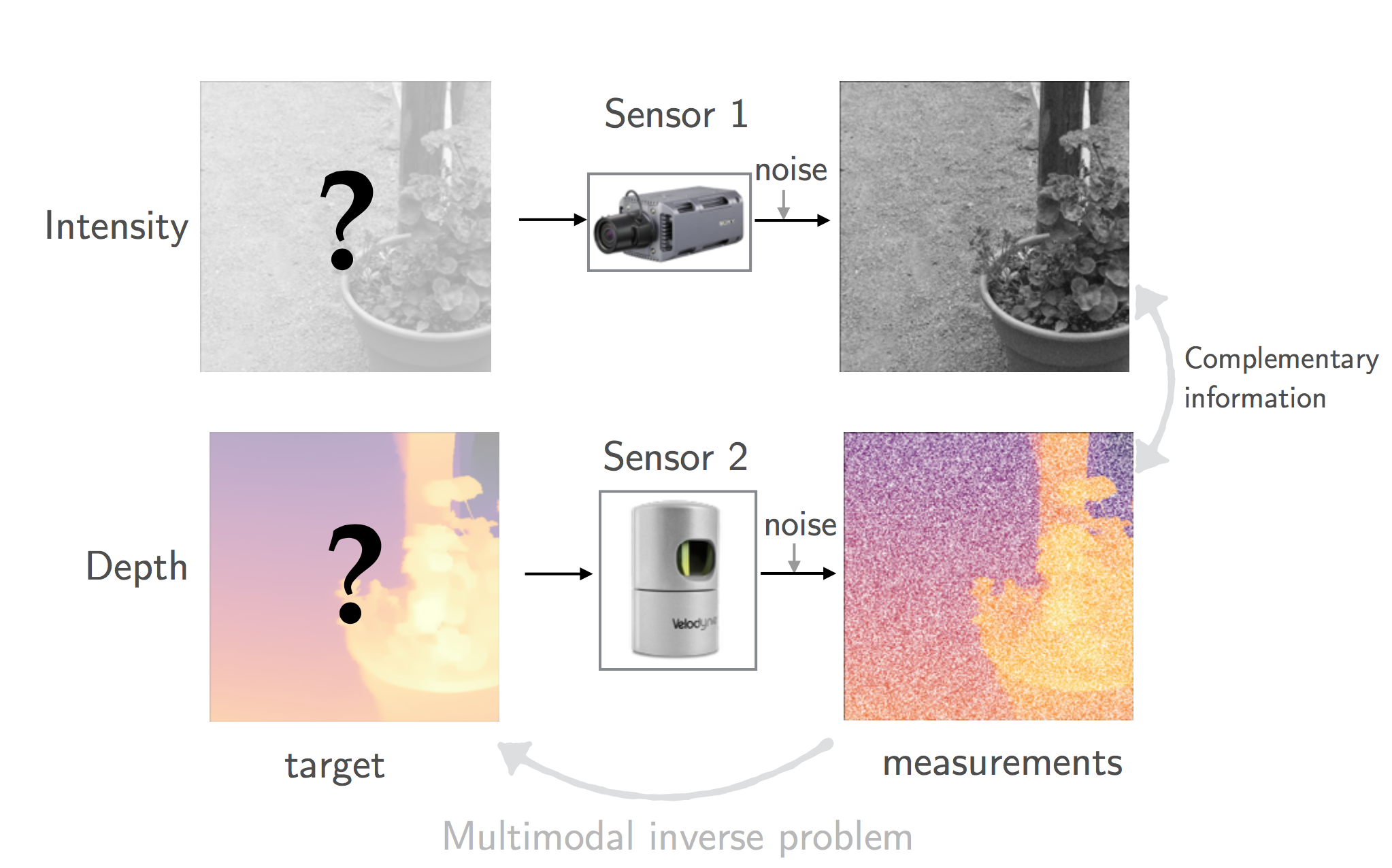
We consider a joint imaging inverse problem with multiple noisy linear measurements as represented on Figure 2. The target images correspond to the same physical object viewed from different modalities. For example, each image may represent a different color channel, spectral band, or a type of sensor. The key insight used in our work is that information about a single modality exists, in some form, in other modalities. This information can be exploited to improve the quality of multimodal imaging, as long as it can be extracted from the measurements.
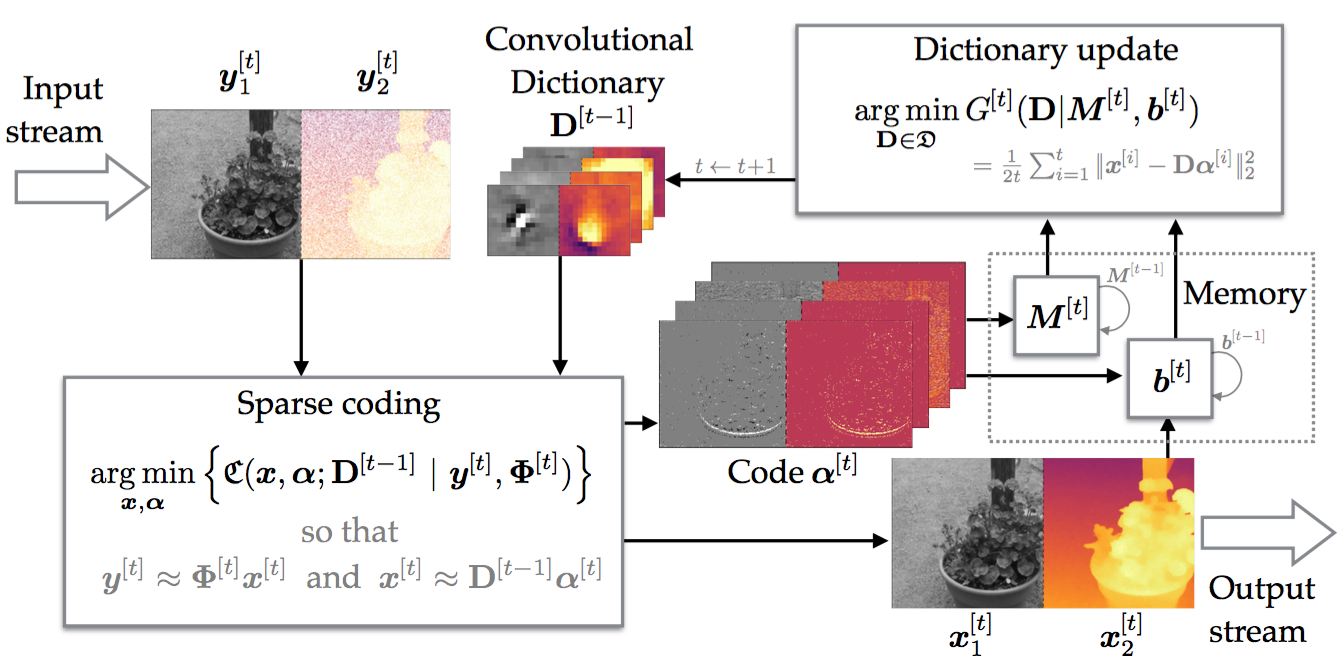
In this work [Entry not found - degraux2017online], we propose a novel approach based on jointly sparse representation of multimodal images. Specifically, we are interested in learning data-adaptive convolutional dictionaries for both reconstructing and representing the signals. The convolutional dictionary learning is performed in an unsupervised way, i.e., given only the linear measurements of the signals. The main benefits of a convolutional approach are that the resulting dictionary is translation invariant and leads to a sparse representation over the entire image. This, however, comes with the increase in the computational cost, which we address by developing a new online convolutional dictionary learning method suitable for working with large-scale datasets. This online formulation behaves, in some way, as a dynamical system, illustrated in Figure 3, where internal state variables are used to keep track of previously reconstructed signals, in a memory-efficient way. If a non-stationary data stream is given to the online learning algorithm, the latter is able to automatically adapt the convolutional dictionary to the changing data distribution. Our key contributions are summarized as follows:
- We provide a new formulation for multimodal computational imaging, incorporating a convolutional joint sparsity prior and a TV regularizer. In this formulation, the high resolution images are determined by solving an optimization problem, where the regularizer exploits the redundancies across different modalities.
- We develop an online convolutional dictionary learning algorithm. By accommodating an additional TV regularizer in the cost, the algorithm is able to learn the convolutional dictionary in an unsupervised fashion, directly from the noisy measurements. The dictionary is convolutional which provides several advantages over a patch-based approach, such as translation invariance and the fact that the size of the atoms does not restrict the size of the associated regularized inverse problem. The online nature of the algorithm makes it appealing for applications that entail very large datasets or dynamically streamed, possibly non-stationary, datasets.
- We validate our approach for joint intensity-depth imaging on two numerical experiments. The first one compares the proposed approach with two competitive intensity-depth fusion algorithms, in an extensive set of simulations over various examples coming from the Middlebury dataset [Entry not found - scharstein2014high], which provides accurate groundtruth depthmaps and high-resolution intensity images. The second experiment aims at demonstrating the dynamic capability of the online algorithm by presenting the results of reconstruction over a depth-intensity video sequence, during which the joint convolutional dictionary visibly improves itself, and the reconstructed depthmap quality, with time.
Collaborators
- Ulugbek S. Kamilov (Washington University in St. Louis, MO, USA, previously MERL, Cambridge, MA, USA)
- Petros T. Boufounos (MERL, Cambridge, MA, USA)
- Dehong Liu (MERL, Cambridge, MA, USA)