On the Importance of Denoising when Learning to Compress Images
Introduction
Image compression is a critical component in digital image processing. The goal of image compression is to reduce the size of an image while preserving its visual quality. However, the presence of noise in an image introduces distortions which can greatly impact the final quality of the compressed image. Noise also results in increased storage cost (bit-rate) due to its unpredictible nature. This is why denoising an image prior to compression is an important step in the image compression process.
We propose training a joint denoising and compression (JDC) neural network whereas a model which is normally trained for image compression (such as [Entry not found - manypriors]) is tasked with image denoising as well.

This joint approach results in a more favorable rate-distortion than the two steps denoising-then-compression approach, while reducing the complexity by an order of magnitude.
We used the compression architecture defined in [Entry not found - manypriors] and explore different training paradigms which share the same base concept: feed the network with a potentially noisy input image and compare the output of the network with a potentially higher quality clean version of the image (rather than with the input image) when computing the distortion loss.
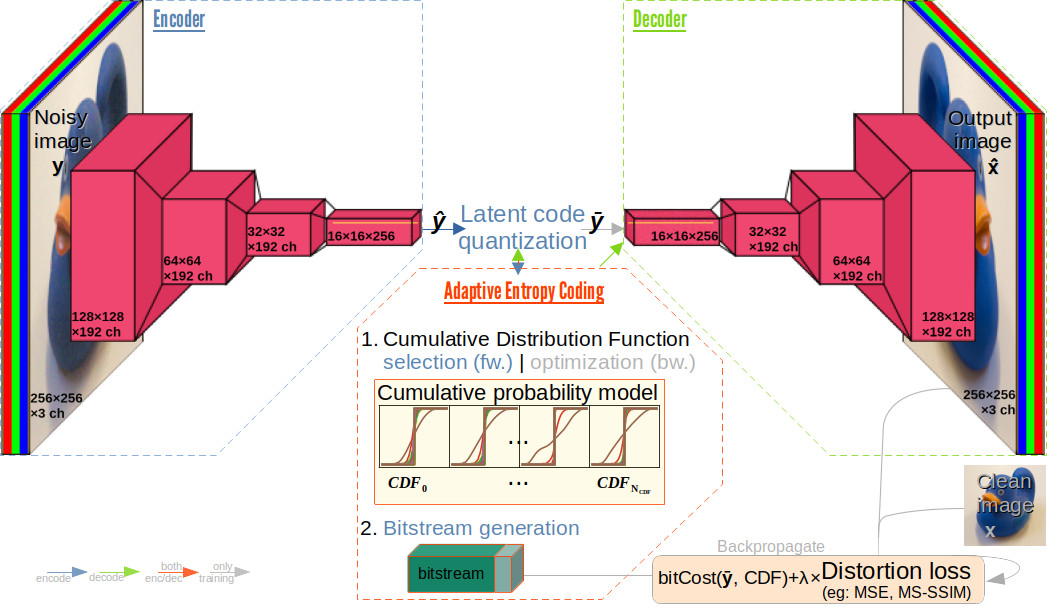
Background
The Natural Image Noise Dataset (NIND) [Entry not found - nind] provides training image sets for which the same scene is captured with varying levels of noise. This is achieved by taking the ground-truth images on a tripod in ideal conditions, then capturing noisy images of the same scene by progressively increasing the shutter speed and ISO sensitivity to less than ideal settings. This allows training a very effective denoiser in a supervised manner. The many varying ISO settings allow for blind denoising where the same model is used for any level of noise. Furthermore we can include (unpaired) high-quality images from other sources in the training data (such as Wikimedia Commons Featured Pictures captured with a low ISO setting) so that the model generalizes well to clean images too.
Methods
The most straightforward approach consists in using clean (x) - noisy (y) image pairs from NIND [Entry not found - nind] to train a supervised model. The rate-distortion performance increases with the addition of some high quality unpaired images (eg 20% of batches), and we can limit the input noise (eg MS-SSIM >= 0.8) so that the model performs well without the need to increase its complexity since extreme levels of noise are not present in most cases. We call this model JDC-Cn.8 (for joint denoising and compression - clean - noisy with 0.8 threshold).
Since a supervised approach is not always feasible, we also propose a self-supervised approach whereas the ground-truth is generated by a denoiser which acts as the teacher network. This allows training from any image data which the denoiser can handle. We call this model JDC-UD (for universal denoiser).
Other methods shown in the results include JDC-CN (trained with clean-noisy image pairs with no noise threshold), JDC-N (trained with only clean-noisy image pairs), and the method introduced by Testolina et al. [Entry not found - testolina] which is trained using artificial noise.
Results
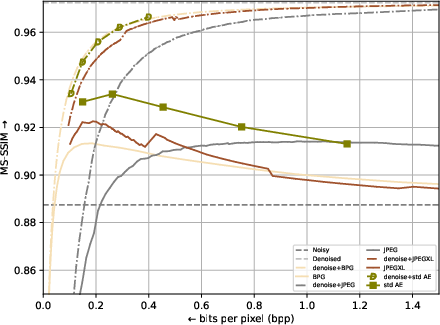
As seen in Figure 1; when compressing noisy data, all schemes (AI models and standards) perform implicit denoising. Given sufficient bitrate, the output quality is better than that of the noisy input. Given even more bitrate, the noise is re-constructed almost identically.
Denoising data prior to compressing (dashed lines) improves the rate-distortion of all models.
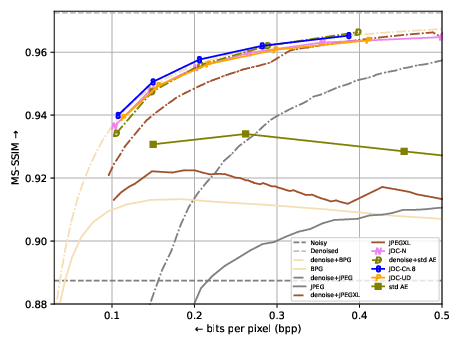
Compression autoencoders trained with a denoising task outperform a U-Net denoiser followed with compression, using 11.2% as much complexity as the two models approach (93 GMACs/MP vs 812 + 93 GMACs/MP)
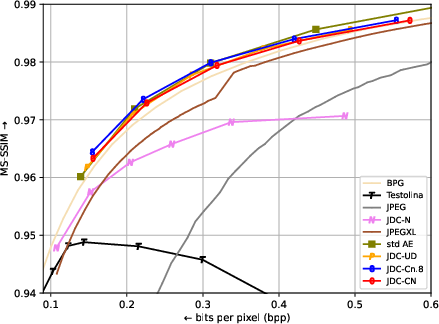
JDC models generalize and perform well with clean images too (CLIC-pro) so long as the training process includes (unpaired) high-quality images. At low bitrates, the MS-SSIM score of JDC models is actually better than that of standard models, until the perception/distortion trade-off favors naive reconstruction.

Conclusion
Incorporating denoising into the training of compression models can improve their rate-distortion performance. The proposed method achieves favorable results on both noisy and clean images, without additional computational complexity associated with image denoising.