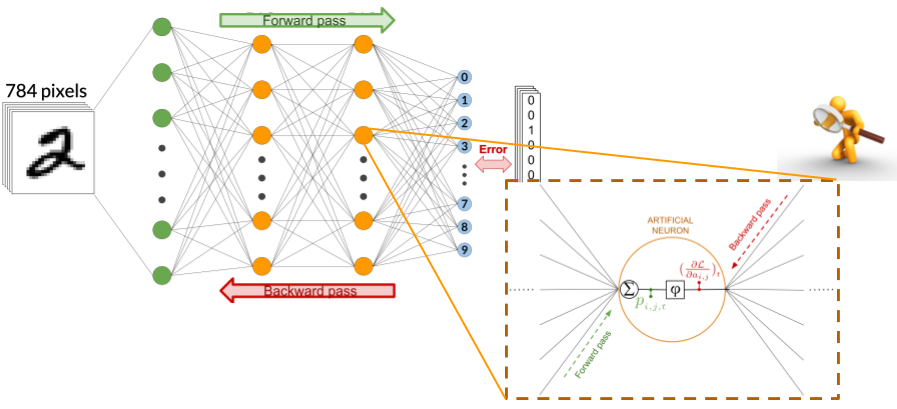
An experimental study of the neuron-level mechanisms emerging during backpropagation-based training
However deep and complex they may be, deep neural networks result from the repetition of a very simple building block: the neuron. This key structural characteristic is however rarely used when studying today’s deep learning models. The reason is simple: the most successful learning algorithm used to train deep neural networks (backpropagation or SGD) is a global and black box optimization procedure rather than a combination of local, neuron-level mechanisms. In such context, the decomposition of deep neural networks in neurons is a priori senseless.
And yet… Our work makes the bet that it might make sense nevertheless, and studies the following research question: could it be that during global, end-to-end training of deep nets, neuron-level mechanisms emerge even though they have not been explicitly programmed? And if they do, can the study of these mechanisms help us understand deep learning, and develop new training strategies?
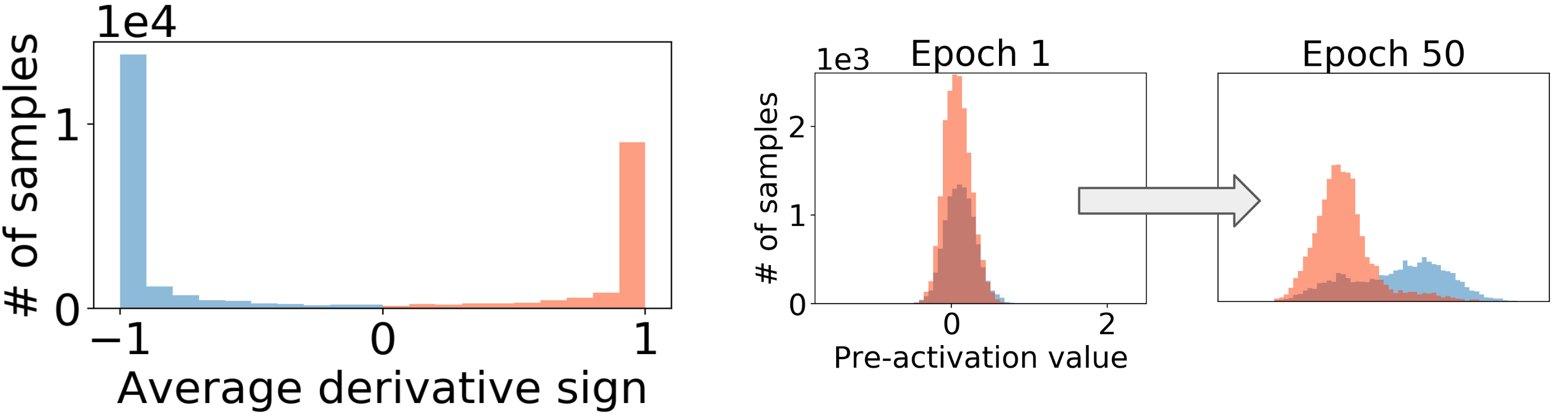
Hidden neurons learn to classify a subset of the data into two categories
Our first main result shows experimentally that neurons behave like binary classifiers during training [2]. Indeed, we observe that the partial derivative of the loss with respect to a neuron’s activation is either always positive or always negative for a given sample, leading the neuron to classify the dataset into two categories (cfr. Figure 2). Additionally, some activation functions such as ReLU cancel the derivatives of samples. This result in a divide-and-conquer strategy, where each neuron can focus on the classification of a (different) subset of samples.
Layer rotation: a surprisingly powerful indicator of generalization in deep networks?
Our second main result studies a metric we call layer rotation. It refers to the evolution across training of the cosine distance between each layer’s weight vector and its initialization. If neurons behave like binary classifiers, training should result in a rotation of the neuron’s incoming weights. The purpose of layer rotation is to measure this behaviour. We discovered that layer rotations have an impressively consistent impact on the generalization ability of a network [Entry not found - boreal:219163]. Additionally, we showed that layer rotations are easily monitored and controlled (helpful for hyperparameter tuning) and potentially provide a unified framework to explain the impact of learning rate tuning, weight decay, learning rate warmups and adaptive gradient methods on generalization and training speed.
Ongoing work
We currently study the divide-and-conquer ability induced by the ReLU activation function (cfr. our first main result). We believe that the amount of samples that activate a ReLU neuron (= the amount of samples that have a positive pre-activation) is an important factor for a network’s expressivity. Stay tuned for our next results!
Related References
- [2] Carbonnelle, S., de Vleeschouwer, C., “Experimental study of the neuron-level mechanisms emerging from backpropagation”; ESANN 2019